Dodging the data bottleneck — data mesh at Starship

Dodging the data bottleneck — data mesh at Starship
A gigabyte of data for a bag of groceries. This is what you get when doing a robotic delivery. That’s a lot of data — especially if you repeat it more than a million times like we have.
But the rabbit hole goes deeper. The data are also incredibly diverse: robot sensor and image data, user interactions with our apps, transactional data from orders, and much more. And equally diverse are the use cases, ranging from training deep neural networks to creating polished visualizations for our merchant partners, and everything in between.
So far, we have been able to handle all of this complexity with our centralized data team. By now, continued exponential growth has led us to seek new ways of working to keep up the pace.
We have found the data mesh paradigm to be the best way forward. I’ll describe Starship’s take on the data mesh below, but first, let’s go through a brief summary of the approach and why we decided to go with it.
What is a data mesh?
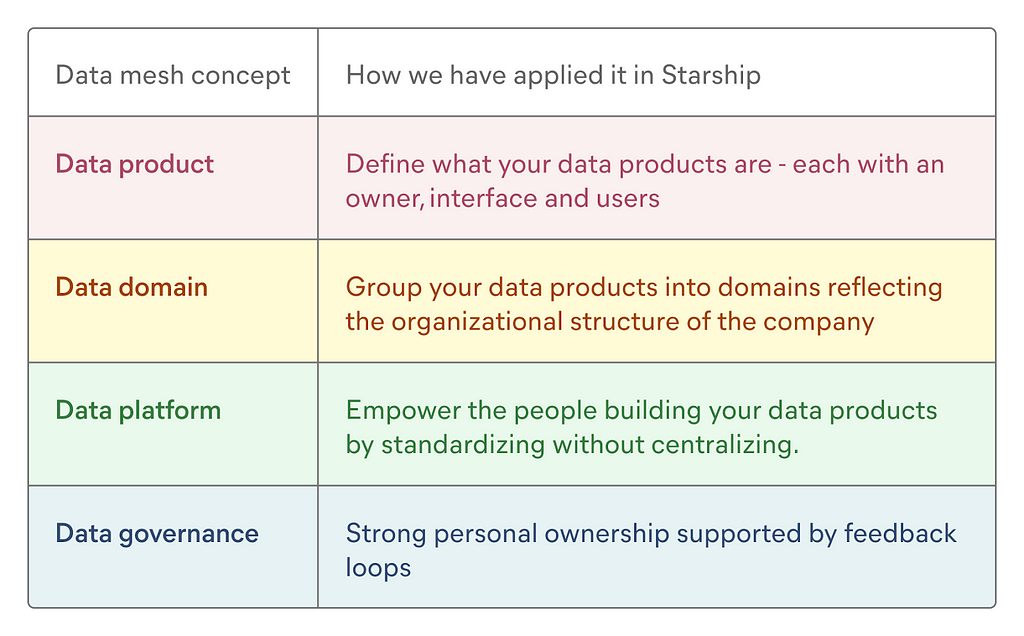
The data mesh framework was first described by Zhamak Dehghani. The paradigm rests on the following core concepts: data products, data domains, data platform, and data governance.
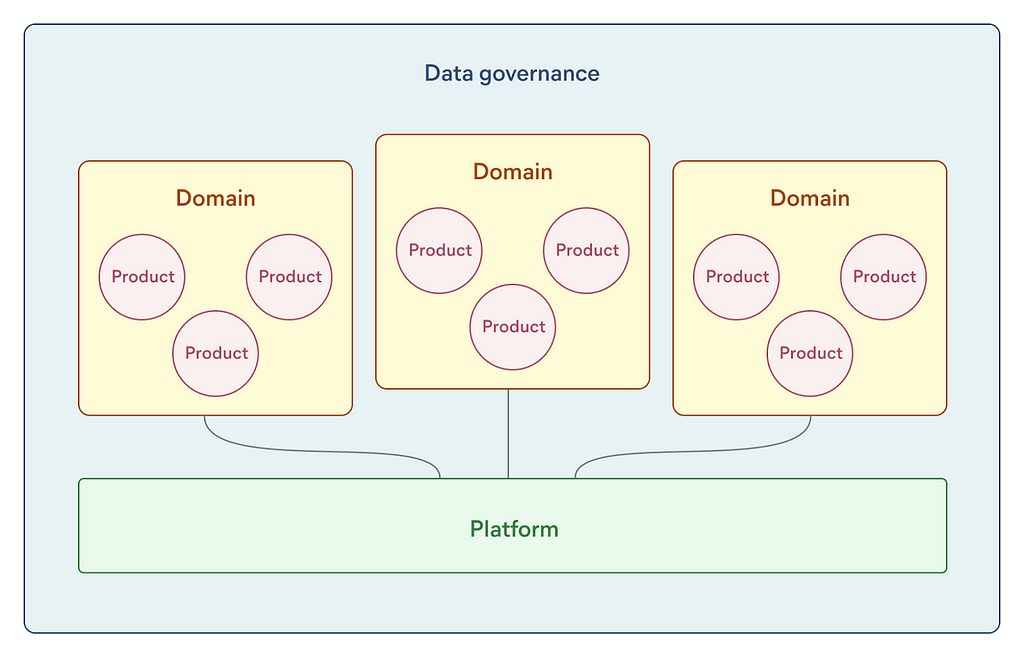
The key intention of the data mesh framework has been to help large organizations eliminate data engineering bottlenecks and deal with complexity. Therefore it addresses many details that are relevant in an enterprise setting, ranging from data quality, architecture, and security to governance and organizational structure. As it stands, only a couple of companies have publicly announced adhering to the data mesh paradigm — all large multi-billion-dollar enterprises. Despite that, we think that it can be successfully applied in smaller companies, too.
Data mesh in Starship
Do the data work close to the people producing or consuming the information
To run hyperlocal robotic delivery marketplaces across the world, we need to turn a wide variety of data into valuable products. The data is coming in from robots (eg telemetry, routing decisions, ETAs), merchants and customers (with their apps, orders, offering, etc), and all operational aspects of the business (from brief remote operator tasks to global logistics of spare parts and robots).
The diversity of use cases is the key reason that has attracted us to the data mesh approach — we want to carry out the data work very close to the people producing or consuming the information. By following data mesh principles, we hope to fulfil our teams’ diverse data needs while keeping central oversight reasonably light.
As Starship is not on enterprise scale yet, it’s not practical for us to implement all aspects of a data mesh. Instead, we have settled on a simplified approach that makes sense for us now and puts us on the right path for the future.
Data products
Define what your data products are — each with an owner, interface, and users
Applying product thinking to our data is the foundation of the whole approach. We think of anything that exposes data for other users or processes as a data product. It can expose its data in any form: as a BI dashboard, a Kafka topic, a data warehouse view, a response from a predictive microservice, etc.
A simple example of a data product in Starship might be a BI dashboard for site leads to track their site’s business volume. A more elaborate example would be a self-serve pipeline for robot software engineers for sending any kind of driving information from robots into our data lake.
In any case, we don’t treat our data warehouse (actually a Databricks lakehouse) as a single product, but as a platform supporting a number of interconnected products. Such granular products are usually owned by the data scientists / engineers building and maintaining them, not dedicated product managers.
The product owner is expected to know who their users are and what needs they are solving with the product — and based on that, define and live up to the quality expectations for the product. Perhaps as a consequence, we have started paying more upfront attention to interfaces, components that are crucial for usability but laborious to modify.
Most importantly, understanding the users and the value each product is creating for them makes it much easier to prioritize between ideas. This is critical in a startup context where you need to move quickly and don’t have the time to make everything perfect.
Data domains
Group your data products into domains reflecting the organizational structure of the company
Before becoming aware of the data mesh model, we had been successfully using the format of lightly embedded data scientists for a while in Starship. Effectively, some key teams had a data team member working with them part-time — whatever that meant in any particular team.
We proceeded to define data domains in alignment with our organizational structure, this time being careful to cover every part of the company. After mapping data products to domains, we assigned a data team member to curate each domain. This person is responsible for looking after the whole set of data products in the domain — some of which are owned by the same person, some by other engineers in the domain team, or even some by other data team members (e.g. for resource reasons).
There are a number of things we like about our domain setup. First and foremost, now every area in the company has a person looking after its data architecture. Given the subtleties inherent in every domain, this is possible only because we have divided up the work.
Creating structure into our data products and interfaces has also helped us to make better sense of our data world. For example, in a situation with more domains than data team members (currently 19 vs 7), we are now doing a better job at making sure each one of us is working on an interrelated set of topics. And we now understand that to alleviate growing pains, we should minimize the number of interfaces that are used across domain boundaries.
Finally, a more subtle bonus of using data domains: we now feel that we have a recipe for tackling all kinds of new situations. Whenever a new initiative comes up, it’s much clearer to everyone where it belongs and who should run with it.
There are also some open questions. Whereas some domains lean naturally towards mostly exposing source data and others towards consuming and transforming it, there are some that have a fair amount of both. Should we split these up when they grow too big? Or should we have subdomains within bigger ones? We’ll need to make these decisions down the road.
Data platform
Empower the people building your data products by standardizing without centralizing
The goal of the data platform in Starship is straightforward: make it possible for a single data person (usually a data scientist) to take care of a domain end-to-end, i.e. to keep the central data platform team out of the day-to-day work. That requires providing the domain engineers and data scientists with good tooling and standard building blocks for their data products.
Does it mean that you need a full data platform team for the data mesh approach? Not really. Our data platform team consists of a single data platform engineer, who is in parallel spending half of their time embedded into a domain. The main reason why we can be so lean in data platform engineering is the choice of Spark+Databricks as the core of our data platform. Our previous, more traditional data warehouse architecture placed a significant data engineering overhead on us due to the diversity of our data domains.
We have found it useful to make a clear distinction in the data stack between the components that are part of the platform vs everything else. Some examples of what we provide to domain teams as part of our data platform:
- Databricks+Spark as a working environment and a versatile compute platform;
- one-liner functions for data ingestion, e.g. from Mongo collections or Kafka topics;
- an Airflow instance for scheduling data pipelines;
- templates for building and deploying predictive models as microservices;
- cost tracking of data products;
- BI & visualization tools.
As a general approach, our aim is to standardize as much as it makes sense in our current context — even bits that we know won’t remain standardized forever. As long as it helps productivity right now, and doesn’t centralize any part of the process, we’re happy. And of course, some elements are completely missing from the platform currently. For example, tooling for data quality assurance, data discovery, and data lineage are things we have left for the future.
Data governance
Strong personal ownership supported by feedback loops
Having fewer people and teams is actually an asset in some aspects of governance, e.g. it is much easier to make decisions. On the other hand, our key governance question is also a direct consequence of our size. If there’s a single data person per domain, they can’t be expected to be an expert in every potential technical aspect. However, they are the only person with a detailed understanding of their domain. How do we maximize the chances of them making good choices within their domain?
Our answer: via a culture of ownership, discussion, and feedback within the team. We have borrowed liberally from the management philosophy in Netflix and cultivated the following:
- personal responsibility for the outcome (of one’s products and domains);
- seeking different opinions before making decisions, especially those impacting other domains;
- soliciting feedback and code reviews both as a quality mechanism and an opportunity for personal growth.
We have also made a couple of specific agreements on how we approach quality, written down our best practices (including naming conventions), etc. But we believe good feedback loops are the key ingredient for turning the guidelines into reality.
These principles apply also outside the “building” work of our data team — which is what has been the focus of this blog post. Obviously, there is much more than providing data products to how our data scientists are creating value in the company.
A final thought on governance — we will keep iterating on our ways of working. There will never be a single “best” way of doing things and we know we need to adapt over time.
Final words
This is it! These were the 4 core data mesh concepts as applied in Starship. As you can see, we have found an approach to the data mesh that suits us as a nimble growth-stage company. If it sounds appealing in your context, I hope that reading about our experience has been helpful.
If you’d like to pitch in to our work, see our careers page for a list of open positions. Or check out our Youtube channel to learn more about our world-leading robotic delivery service.
Reach out to me if you have any questions or thoughts and let’s learn from each other!
Taavi Pungas – Data Team Lead – Starship Technologies | LinkedIn
Dodging the data bottleneck — data mesh at Starship was originally published in Starship Technologies on Medium, where people are continuing the conversation by highlighting and responding to this story.





